Site Woes
HostingMatters appears to be having some sort of trouble, as OTB has been down the last couple hours and on only intermittently the last few minutes, and PoliBlog has had the same problem.
Can you tell when the site went down?
These things happen, but that doesn’t make it any less aggravating. (And, yes, I paid my bill!)
Update (1431): I just got the following note from HostingMatters:
Your site was consuming too much cpu time which is against our AUP and making the server completely unstable not only affecting your site but all of the other sites on that server. I suspended it so that our others on the site would not be affected by you. I have unsuspended it temporarily to see how it goes.
Considering that they didn’t bother to contact me first and that there’s no obvious reason why the site would be “consuming too much cpu time”– I’ve certainly had much higher traffic in recent months — I’ve gone from “aggravated” to really pissed off.
Update (1446): Much better now:
Apparently your postings about the most recent beheadings have landed you in the top spots for certain searches.
In any case, your site is going to be moved off [old server name] to a new server. I’ll be finishing the buildout of that box this afternoon or evening, and moving your site overnight.
Fair enough. I’ve gotten surges after beheadings before, although not this much since the Nick Berg incident back in May (where I had a whole lot more traffic). Since I’m not actually hosting videos or anything, I didn’t think it would have been that big a bandwidth drain. The only thing I can figure is that my category archive for “Hostage Beheadings” has itself gotten a lot of hits. But it only shows 15 posts at a time. Oh, well.
Update (1715): This would clear things up if I understood the techology involved:
This is not a matter of the number of visits or of bandwidth. It is a matter of the number of processes generated by those visits. The mySQL processes in particular that are attached to your account are creating the most problems at the moment.
I can wrap my head around the bandwidth concept but don’t understand this one. At any rate, they’re having to keep the site alive manually until they can move it to a new server this evening.
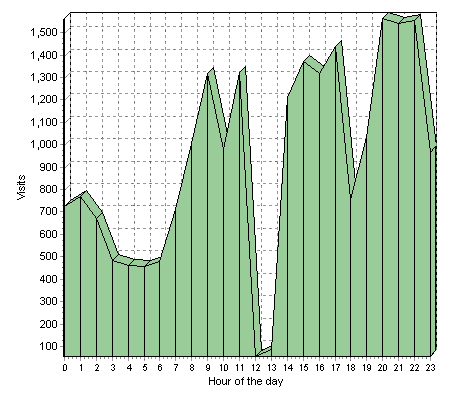
Update (1837): Another extended outage. The SiteMeter graph above has been updated to track this odyssey.
Update (1840): I was apparently “utilizing 492 of the 500 available mySQL connections.” How/why, I couldn’t tell you.
Update (1940): They’ve moved me to a new server. Hopefully, I won’t overwhelm that one.




Noticed it about 12 or so, and it just started resolving a few minutes back, about 2pm Eastern. Glad you’re back! No reasons as to why this has happened? We were speculating that you hadn’t paid the bill, based on the “error” message that came up.
IT WAS A CONSPIRACY BY RADICAL LEFT-WING INTERNET TERRORISTS, TO SILENCE COMMON SENSE AND PREVENT THE TRUTH FROM BEING KNOWN!
THE GOVERNMENT SHOULD IMMEDIATELY LAUNCH AN IN-DEPTH INVESTIGATION TO EXPOSE THE PERPETRATORS!
Well duh, now the chart is working – looks like I fell in the same category with everyone else.
now you know why I do not post about beheadings…
Yeah, but you knew some us us had to rib you. 😉
Not even Instapundit could crash a WP-powered blog on a decent enough server—which I believe HM’s are—so I was quite surprised with the whole b3heading search surge causing CPU overuse.
There’s a diff. between CPU load and server traffic load. The former is a bigger PITA for server admins; there is the staticize plugin for WP that can help alleviate these problems, although I wouldn’t know, for the life of me, how to go about implementing it.
James,
You’re actually quite lucky. More than a few admins I know would have booted you off of their servers without explanation.
Anyway, from your snippets, I’m guessing that the database is being queried for those 15 or so posts all at once. As far as I understand it, each time a person requests a page your database is being queried.
So, instead of having the problems of having one popular post linked (which i think would be cached), you have people trying to get to 15 different posts, which is a drain on the database.
Also, you’re on WP, so that too could be contributing to your issues…
I have experienced a pretty big spike over the last couple of days myself from Google searches for the Berg matter, although, it is also nowhere near as big as the one I got right after the event.
I suspect that each and every inline comment is causing a database query when the page is assembled, rather than when someone decides to check the comments to a specific post. Possibly every post on the front page also causes a database query, but that’s a lot easier to cache.
I had the identical problem with a different host once I switched to WP. The host went ballistic and I had to switch; they weren’t nearly as nice about it and made me sound like a pornographer with their warning message, which referenced objectionable content without explaining it was a resource issue on their server. Almost identical and I didn’t have inline comments of any kind.
Interesting. Of course, I’ve had inline comments for months with no problems until now.
I don’t know exactly why it happened, I was just mentioning that I didn’t have inline comments to add to the comment above. In other words, I don’t think they are the issue. It took a few weeks before the problem materialized. All I’m saying.
Well, the “MySQL was maxing out” makes more sense than bandwidth issues, which should be easily handled by the server.
The main difference between WordPress and Movable Type is that Movable Type would make a new index page after you posted a new entry, and be done with it. Also, all archive links were generated when you posted. Thus, after updating the database, SQL (the program that keeps your information) wasn’t utilized that much. I think it was checked when you loaded the index page, but if you clicked a specific page (like someone looking up a beheading article), the database wasn’t checked at all.
In the case of WordPress, the pages are generated on the fly. Thus, a spike in bandwidth causes a spike in SQL activity, which probably explains your problems. There are advantages and disadvantages to both of these methods.
Did your SQL database ever go down when you were running Movable Type? If it ever did (as mine did once), the pages still worked, because they had been generated and saved as individual files – the measure that saved looking things up in the database. WordPress does not do this – no matter how you specify things, the pages are loaded through the “index.php” file you use to start the site.
I do find it interesting that the site went down, though, as most web programs today that use SQL databases use the WordPress method – you’d figure hosts would be ready for it. Anyway, I hope things work out.
I tried to “non-techify” that explaination, and wouldn’t be surprised if I failed. Hopefully, this leads to at least a slightly better understanding of the problem.
(Note: this is why any changes to the site itself would require a rebuilding of all the files – they were static, whereas WordPress is dynamic. This is one of the advantages of the WordPress method.)